For those who know me, you’re likely aware that I co-founded Lexset with a vision to transform how deep learning models are trained using simulation. Our mission goes beyond creating responsible and ethical datasets—we’re building the infrastructure that empowers engineers to design targeted data points, shaping the specific concepts AI models learn and enhancing their ability to extract specialized features. If you can engineer your datasets, you can engineer what and how an AI learns.
This is an abstract concept that can be hard to grasp. In this post, I’ll provide a few clear examples to illustrate the connection between the dataset’s content and the model’s weights. While Lexset’s work typically involves generating highly complex datasets through 3D physics-based simulations, I’ll simplify things here by using a basic algorithmically generated dataset of shapes. This simpler approach allows us to introduce targeted features into the data and observe their impact on the model’s learned weights.
Model Architecture#
For these experiments, we’ll use a simple convolutional neural network (CNN) to classify images into three categories. The model processes images in stages through four convolutional layers, each designed to detect progressively more complex features—starting with edges, then textures, and eventually patterns. Pooling layers follow the convolutional layers to reduce the image size while preserving important details, improving efficiency.
Once the image is processed, it’s flattened into a one-dimensional list of values and passed through two fully connected layers that make the final classification. The model uses ReLU activation functions, which enable it to learn complex patterns effectively. To gain insights into what the model learns at each stage, we’ve added visualization hooks to monitor the features captured by each layer.

Our Experiments#
Experiment 1: Basic Shapes on a Black Background#
We will start with the simplest possible dataset: a randomly generated colored shape on a black background.
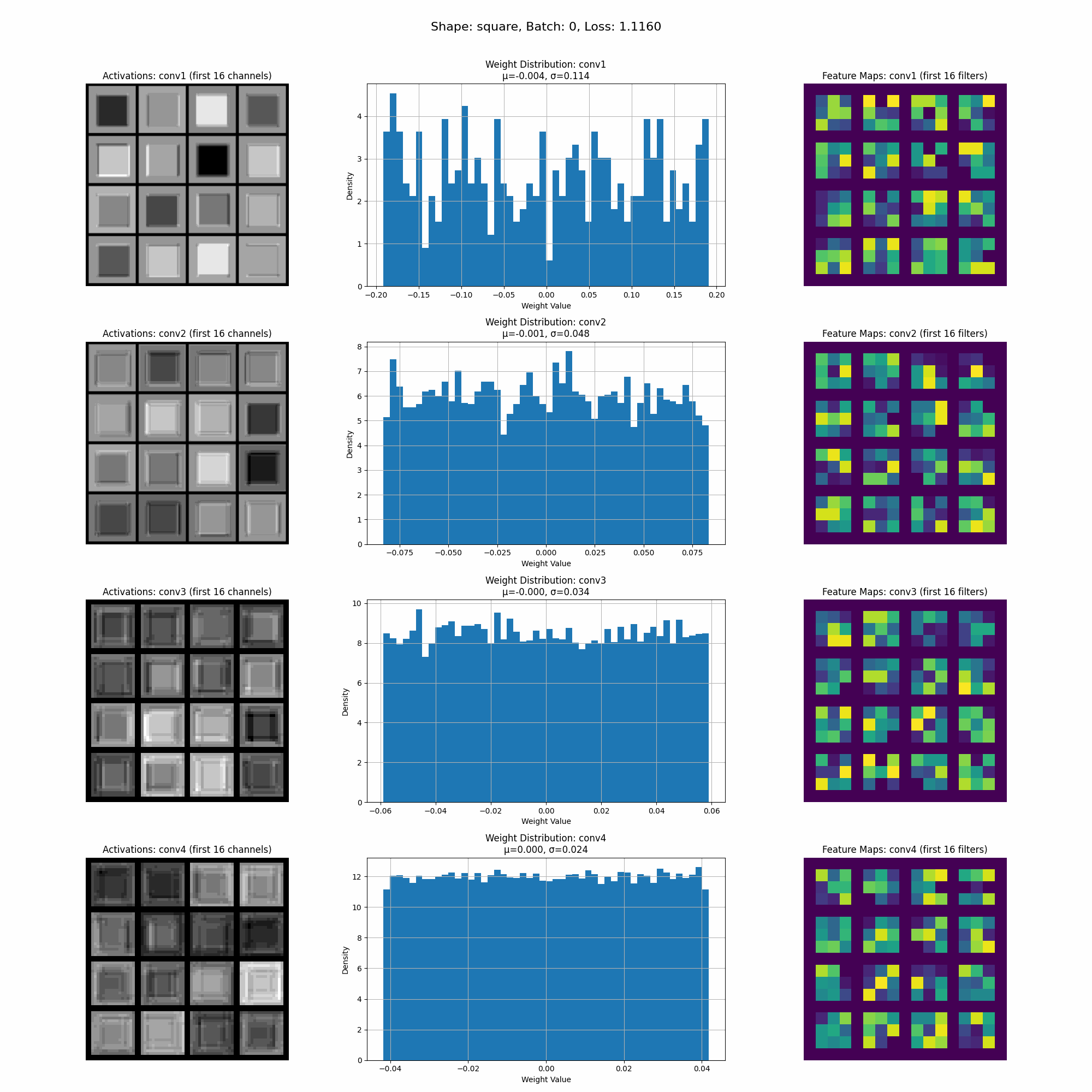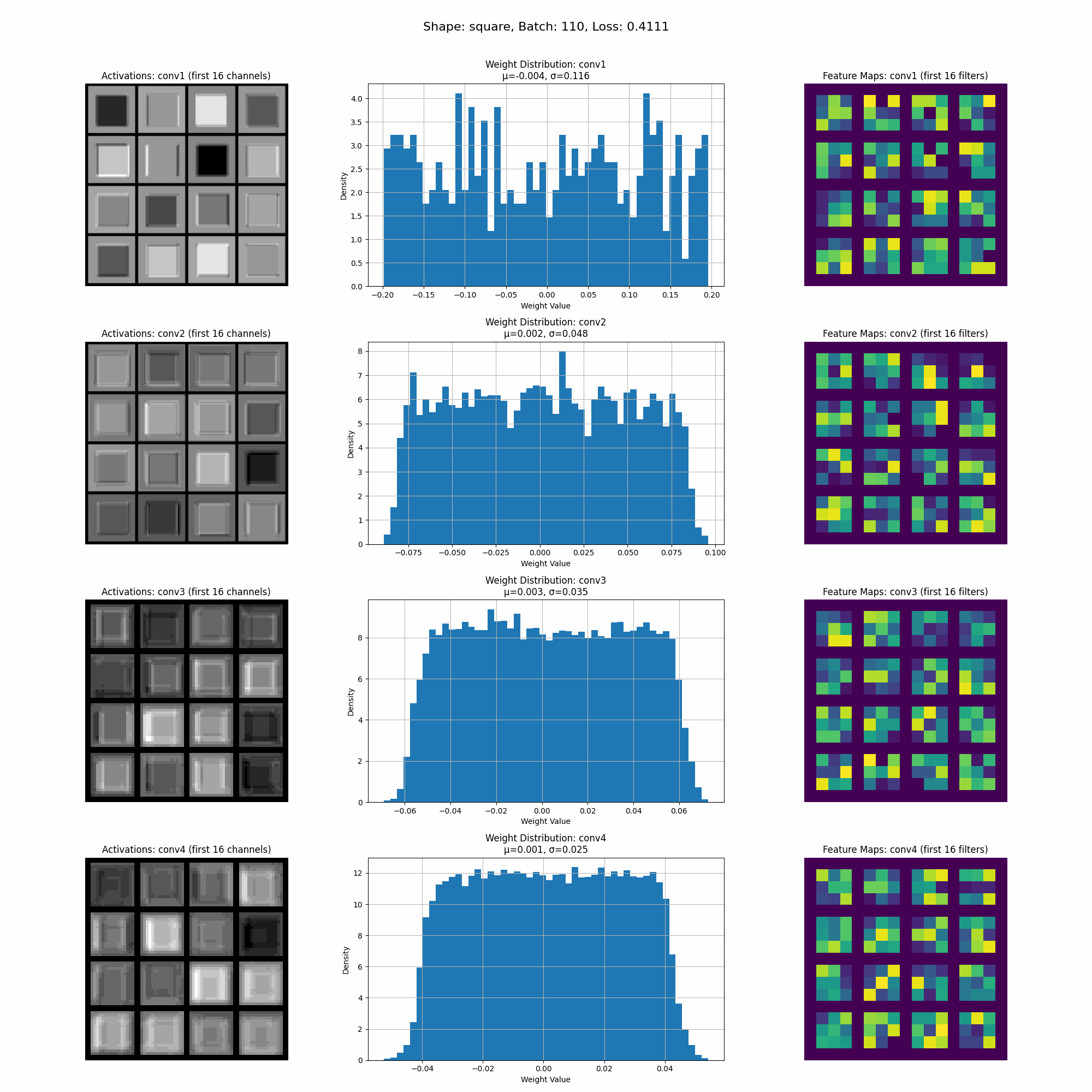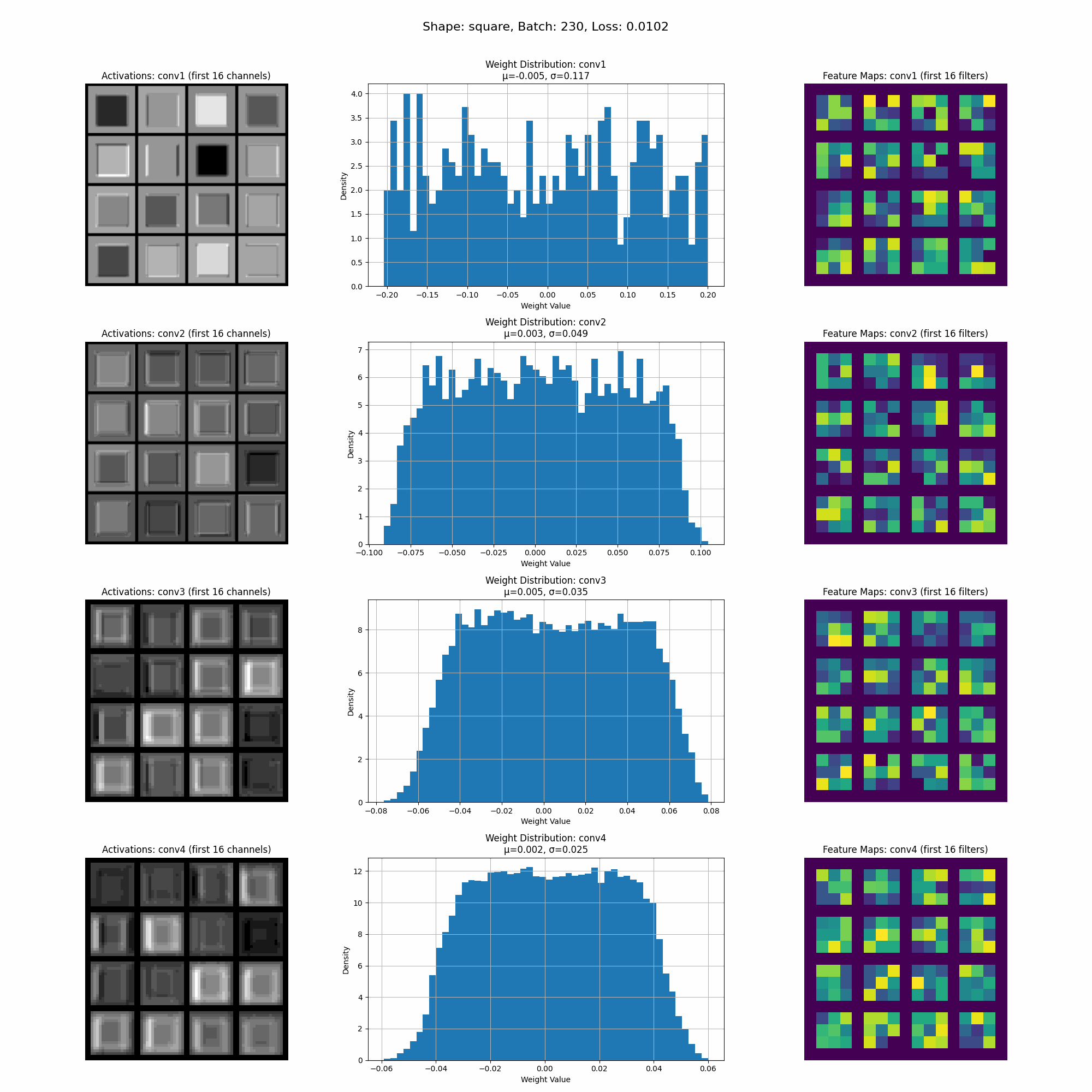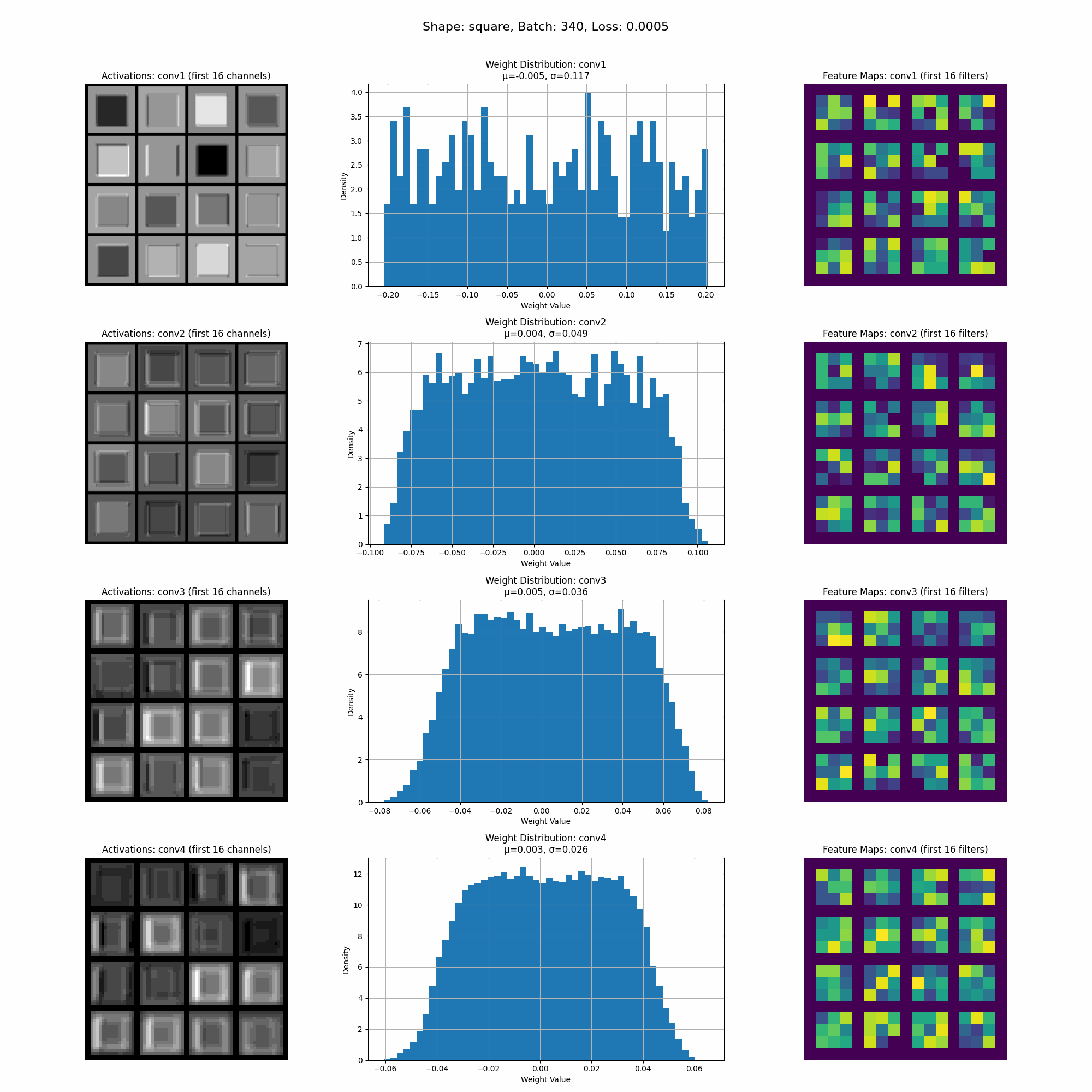
The model converges quickly, and in the visualization below, you can see how the activations and weights evolve during training. We will continue to refer back to this visualization as we explore the impact of different datasets.

This is a visualization of the activations as the model trains.
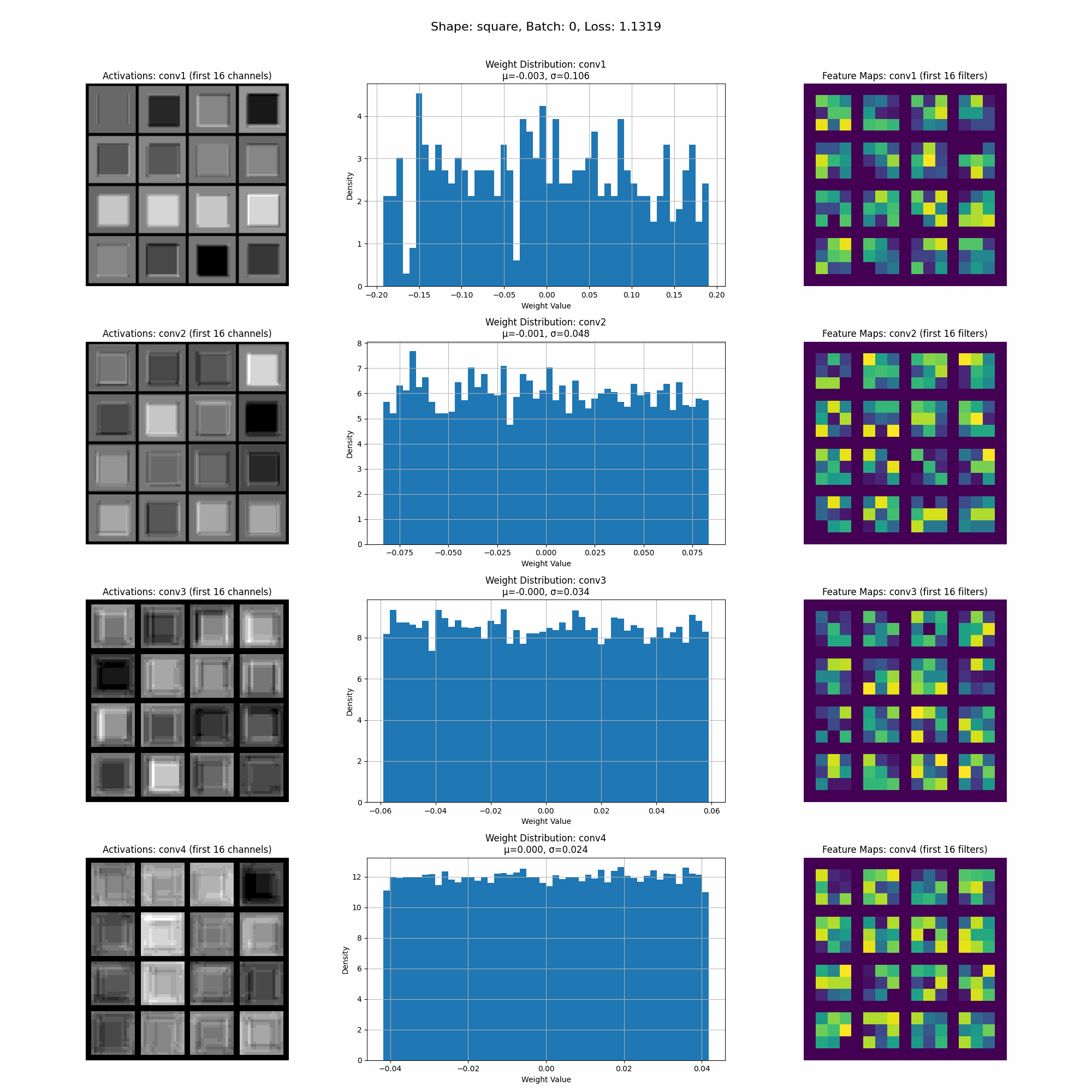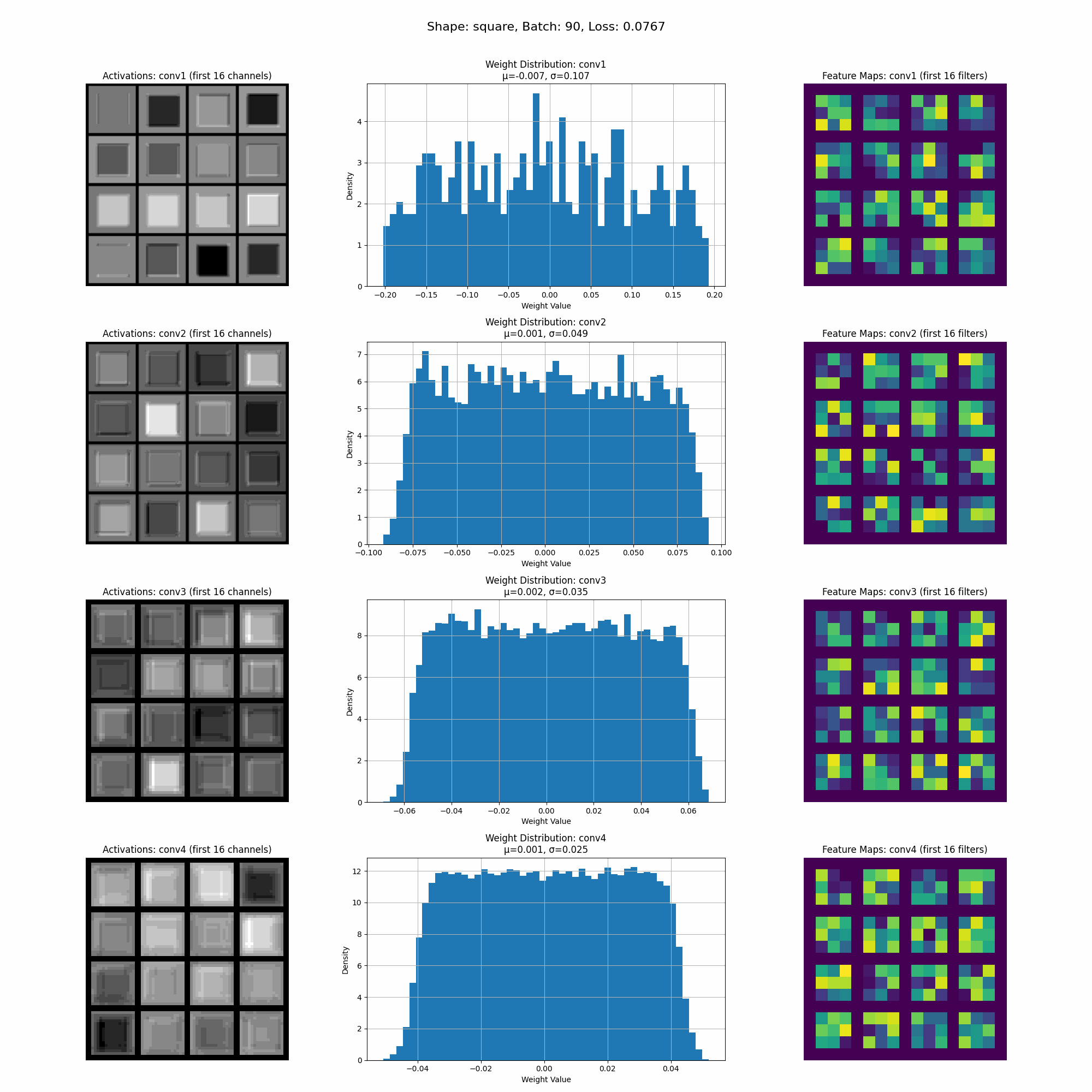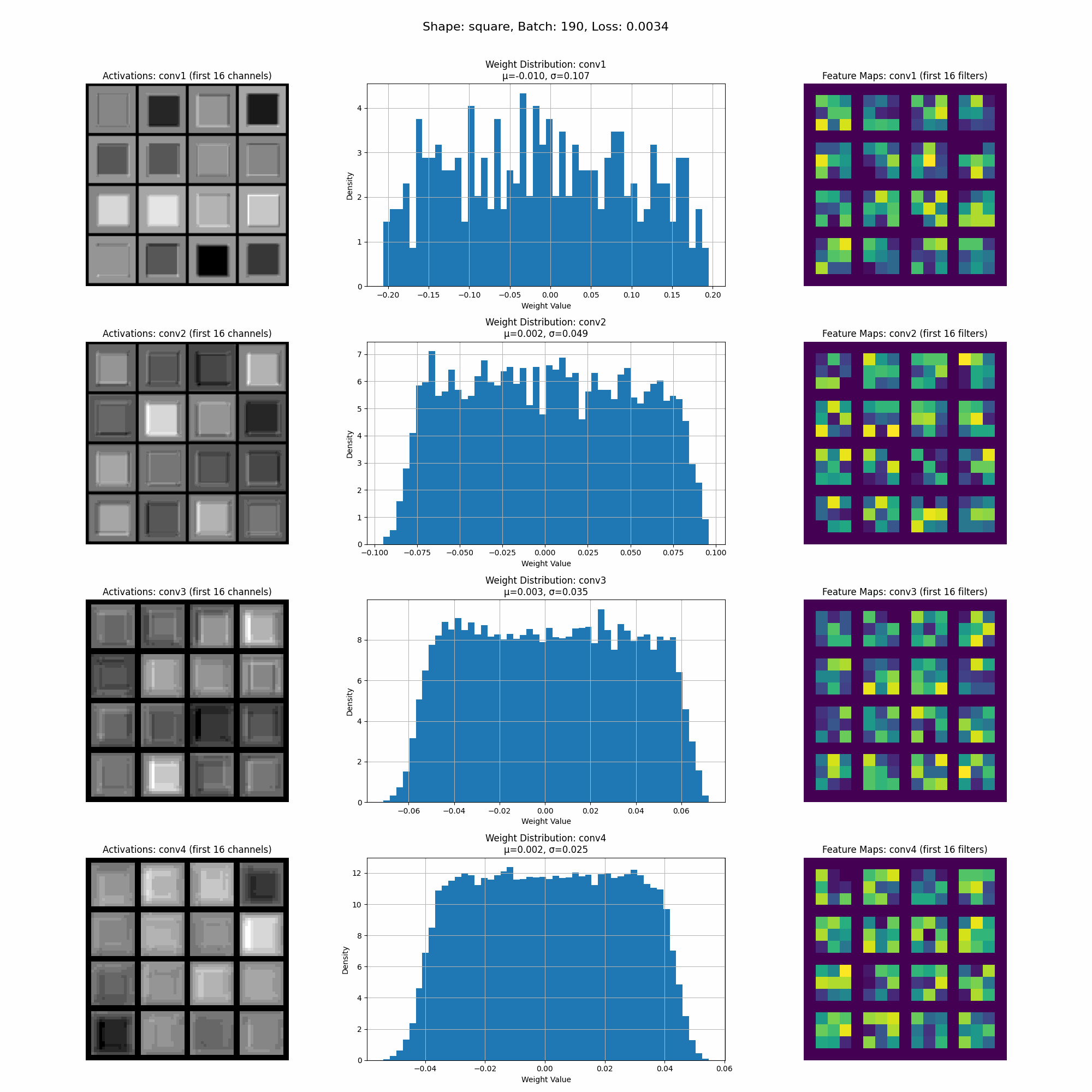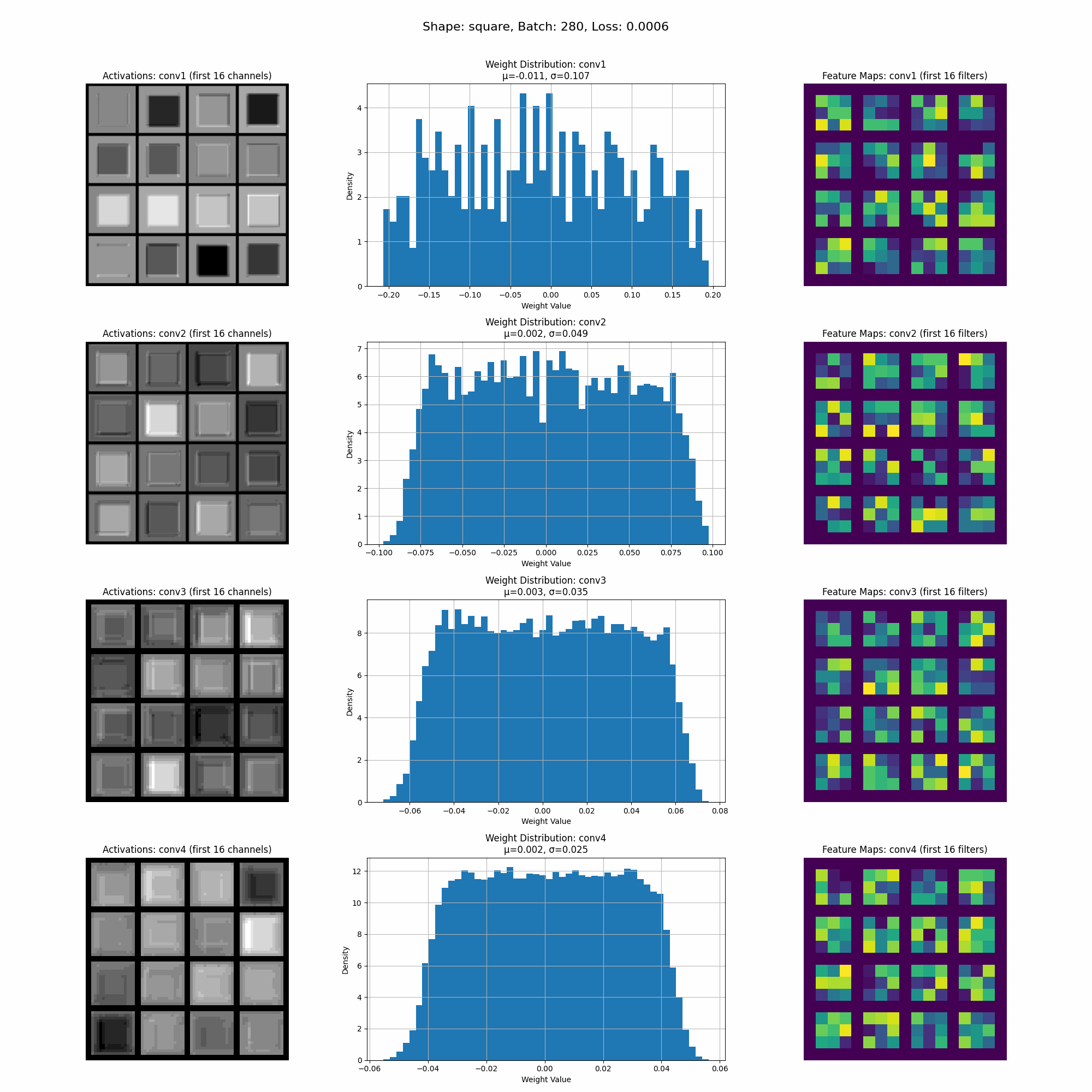
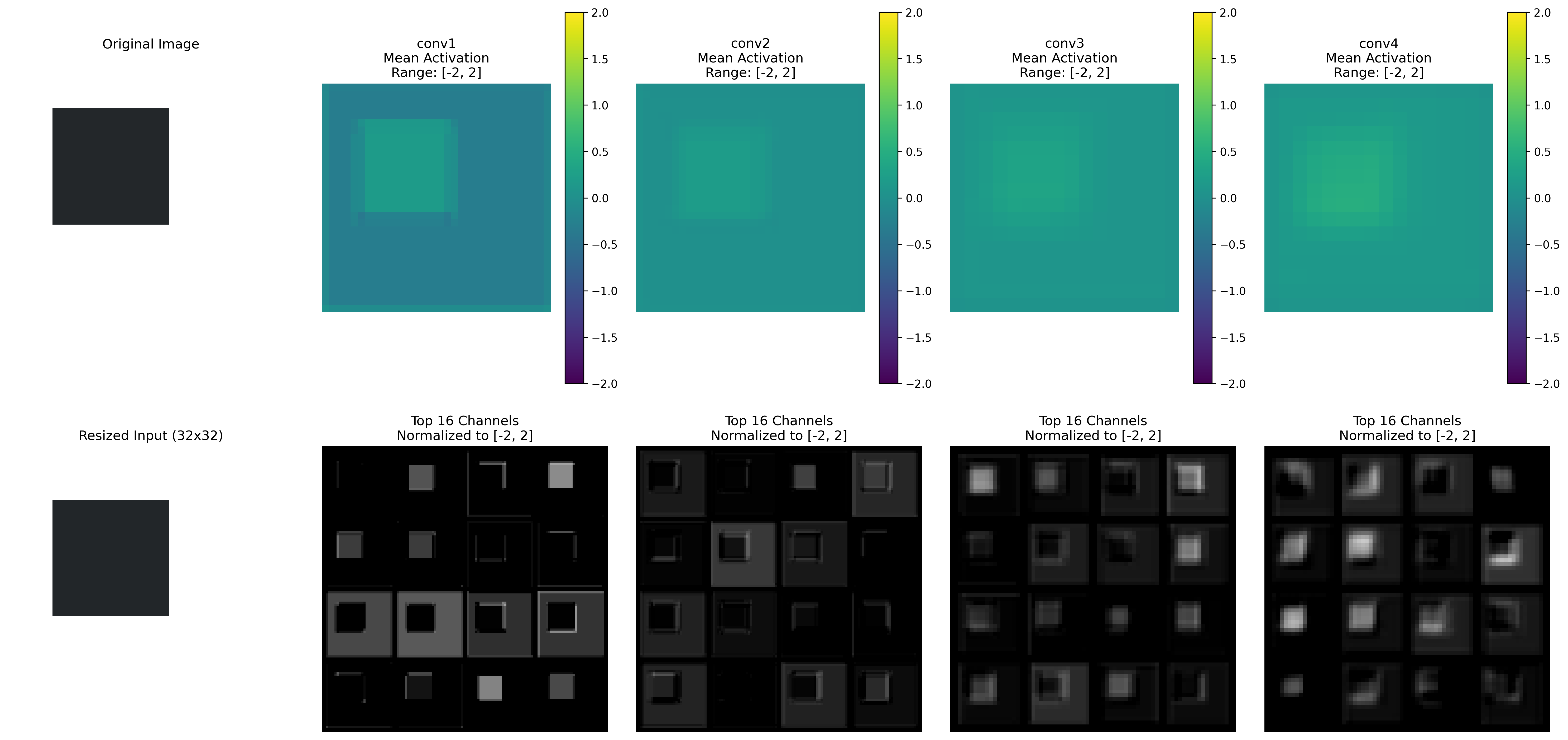
In this image we can see the activations for a specific shape at inference time. Take note of the intensity of the activations accross different parts of the shape.
Experiment 2: Introducing Random Backgrounds#
In the next experiment, we introduce a randomly colored background to the dataset.
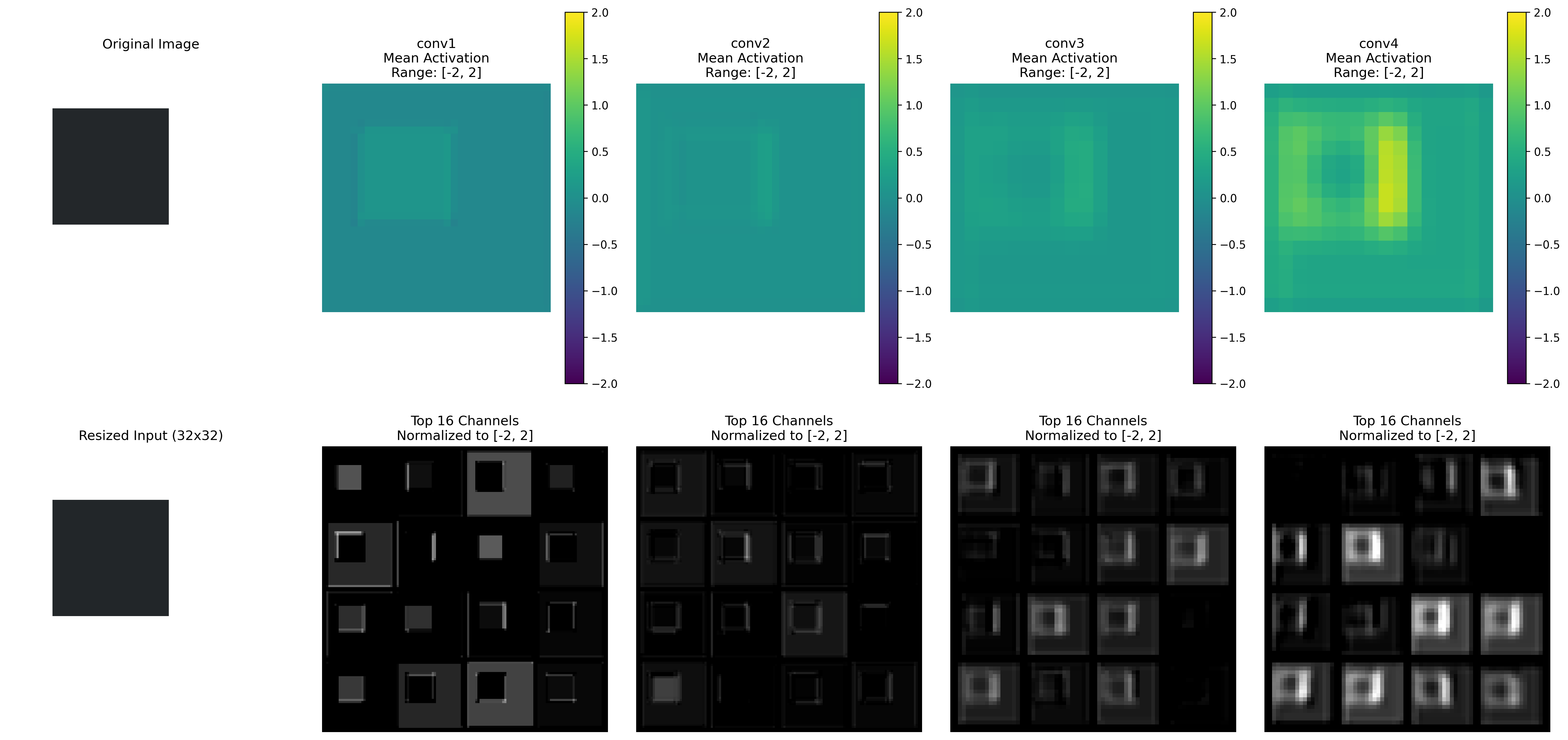
This may seem like a minor change, but it significantly impacts the model’s activations. It is especially noticeable in the lower layers of the network.
Previously, the intensity of the activations was distributed across the entire shape. However, with the introduction of the random background, we observe that the model focuses more on detecting edges in the activations.
Take note of how the activations change in this version of the model. Especially in the lower layers of the network.
Experiment 3: Shape Orientation and Activation Patterns#
Another interesting observation from our tests is that when the model encounters a square, the strongest activations tend to be concentrated on one side of the shape. Since this is a simple example, we can reason our way into how this behavior might emerge.
One possible explanation could be that the squares in our dataset are always in the same orientation. The model has no incentive to learn the full boundary of a square. Instead, it can achieve the classification task by simply recognizing the presence of a vertical line. On the other hand, the triangle contains a horizontal line and two angled lines, making it more complex. This suggests that a vertical straight line is an important feature within this feature space.
However, when we introduce random rotations to the shapes, we notice significant changes in the model’s activations, indicating that the model is now learning more comprehensive shape characteristics.

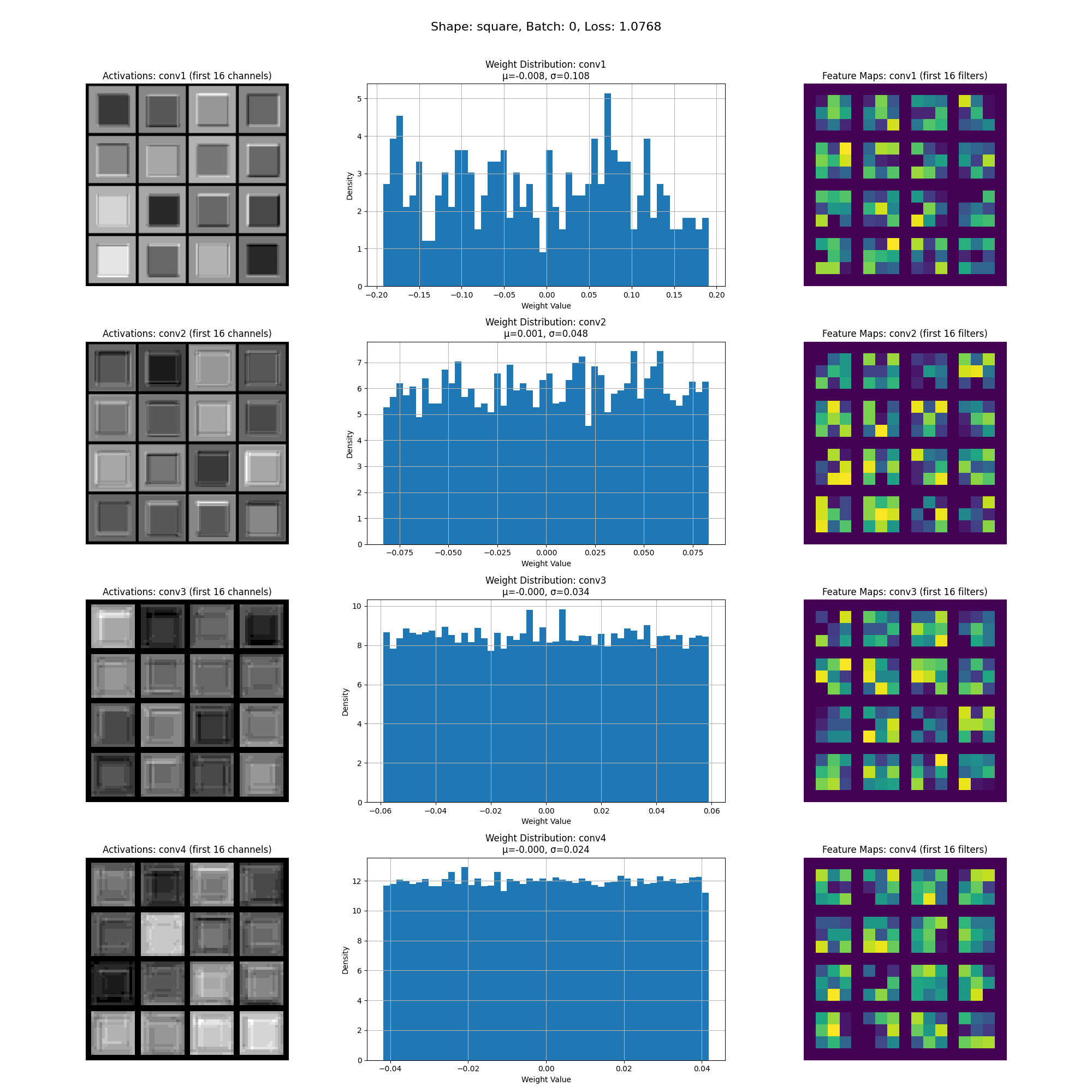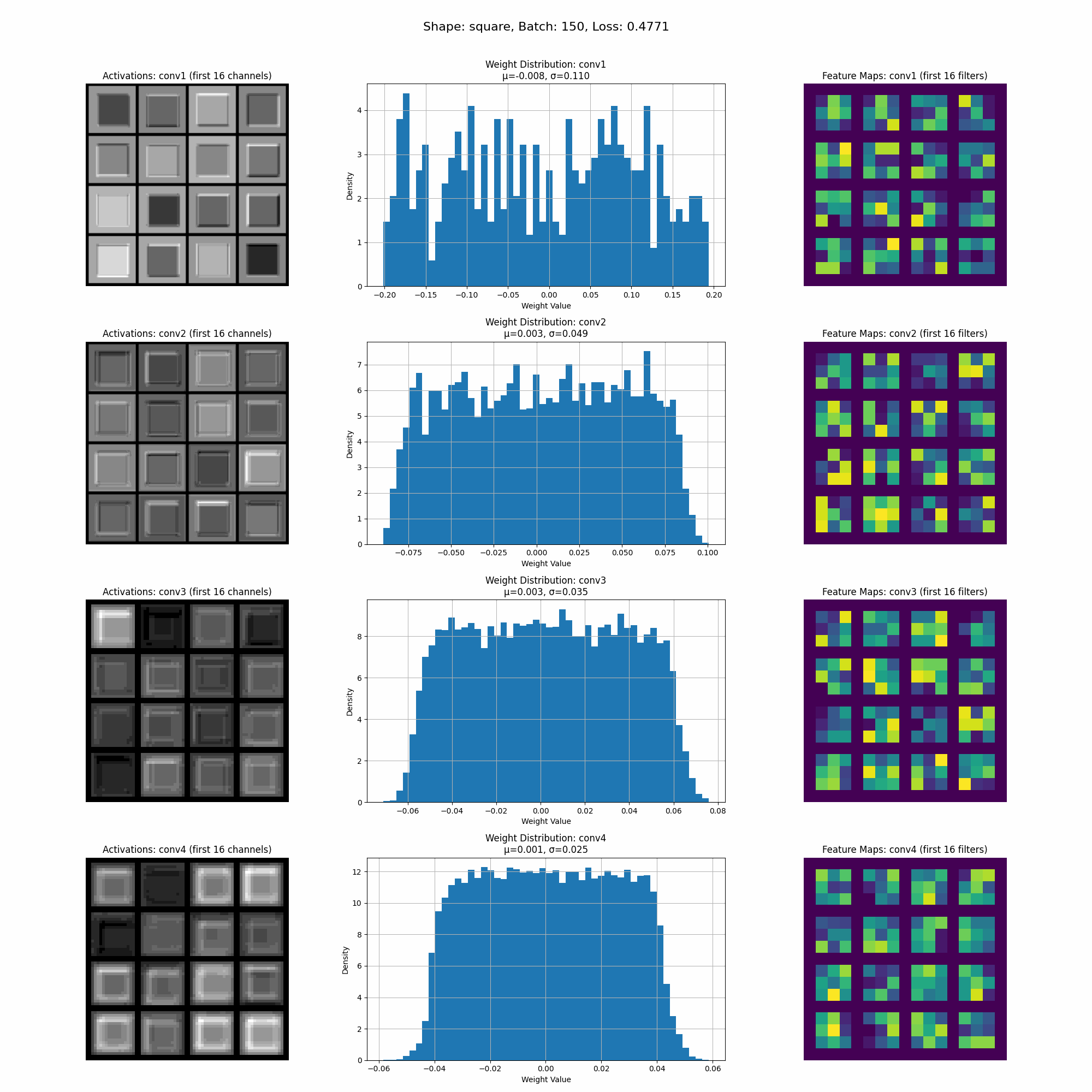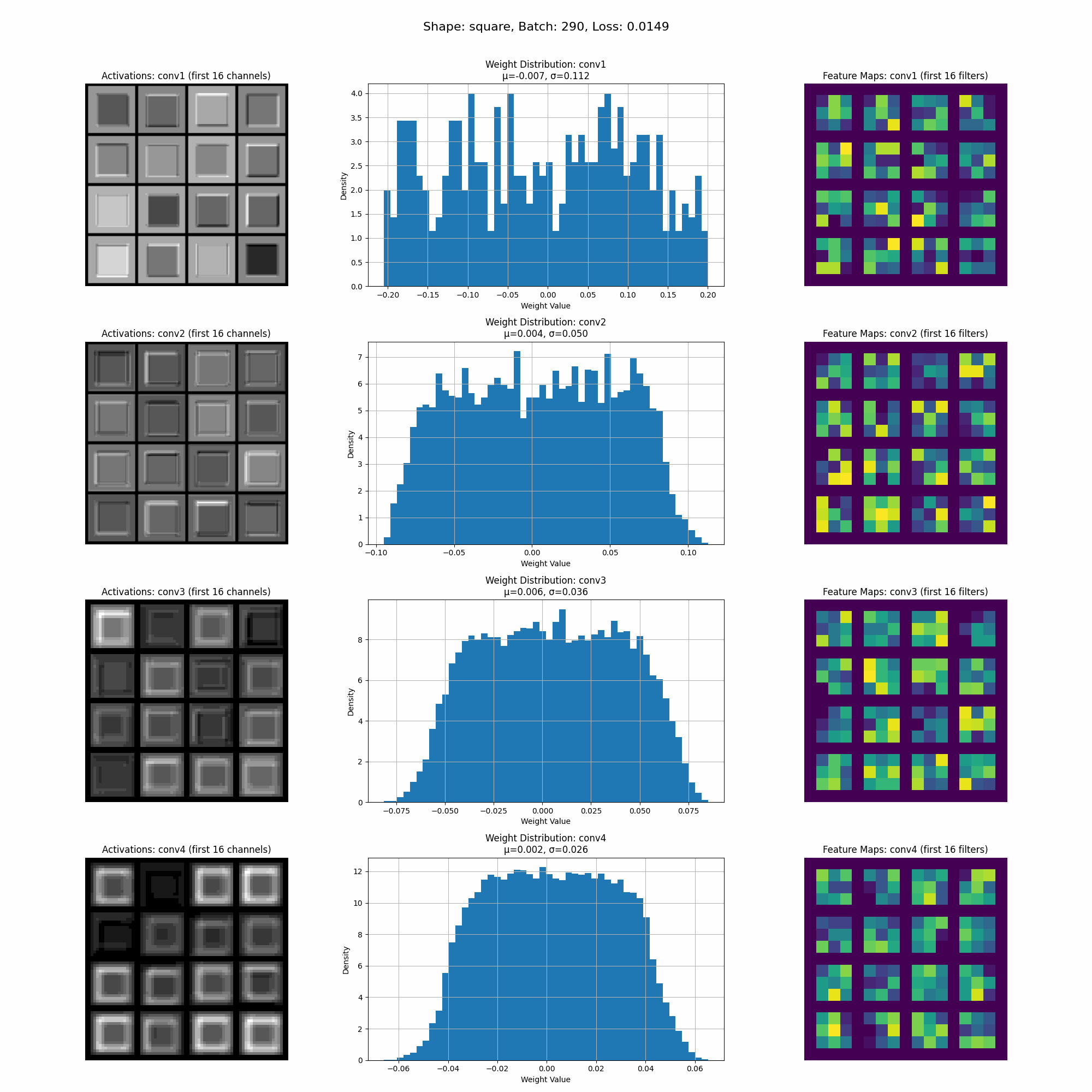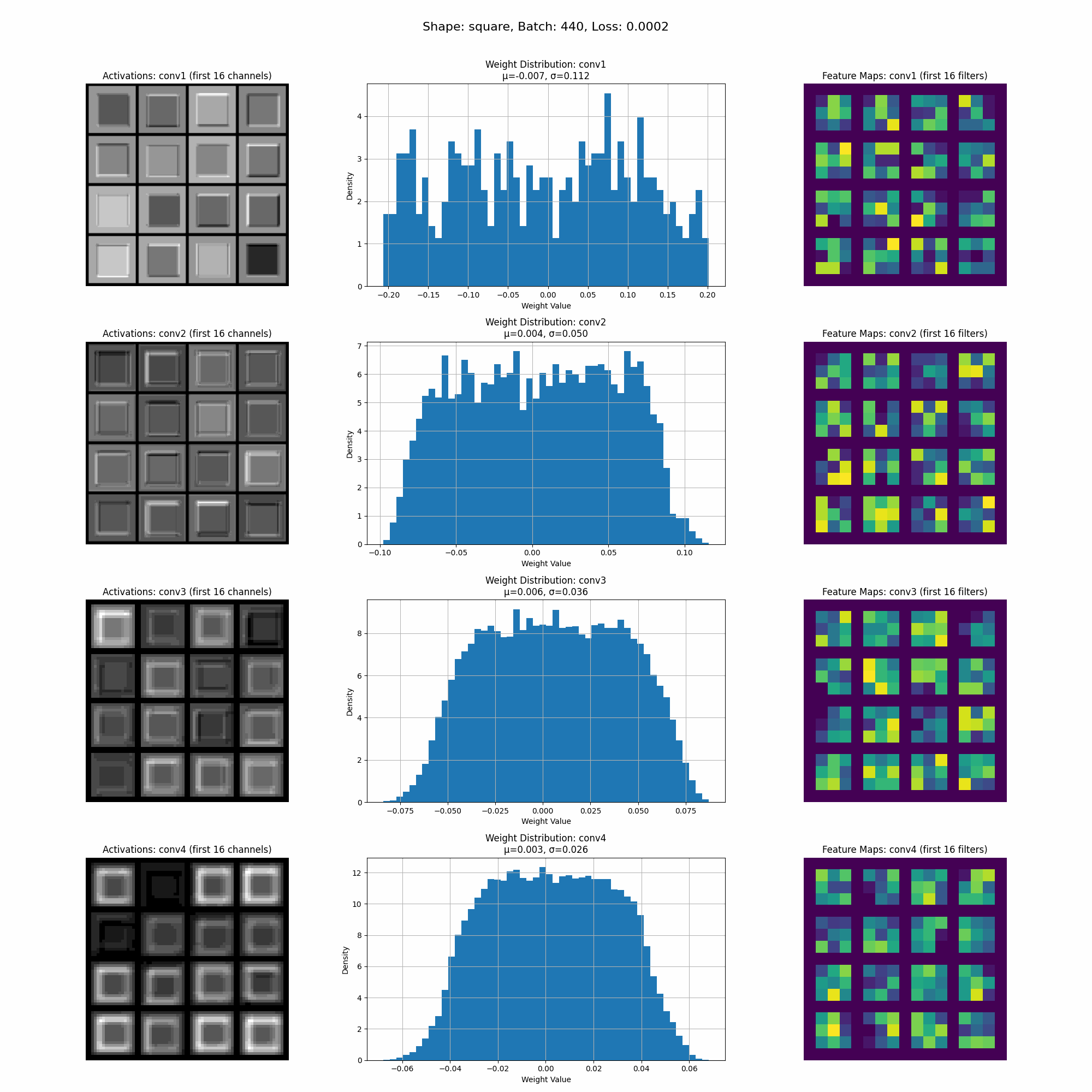
As you can see from the activations the model is now learning more comprehensive shape characteristics. The activations are more spread out across the perimeter of the shape.
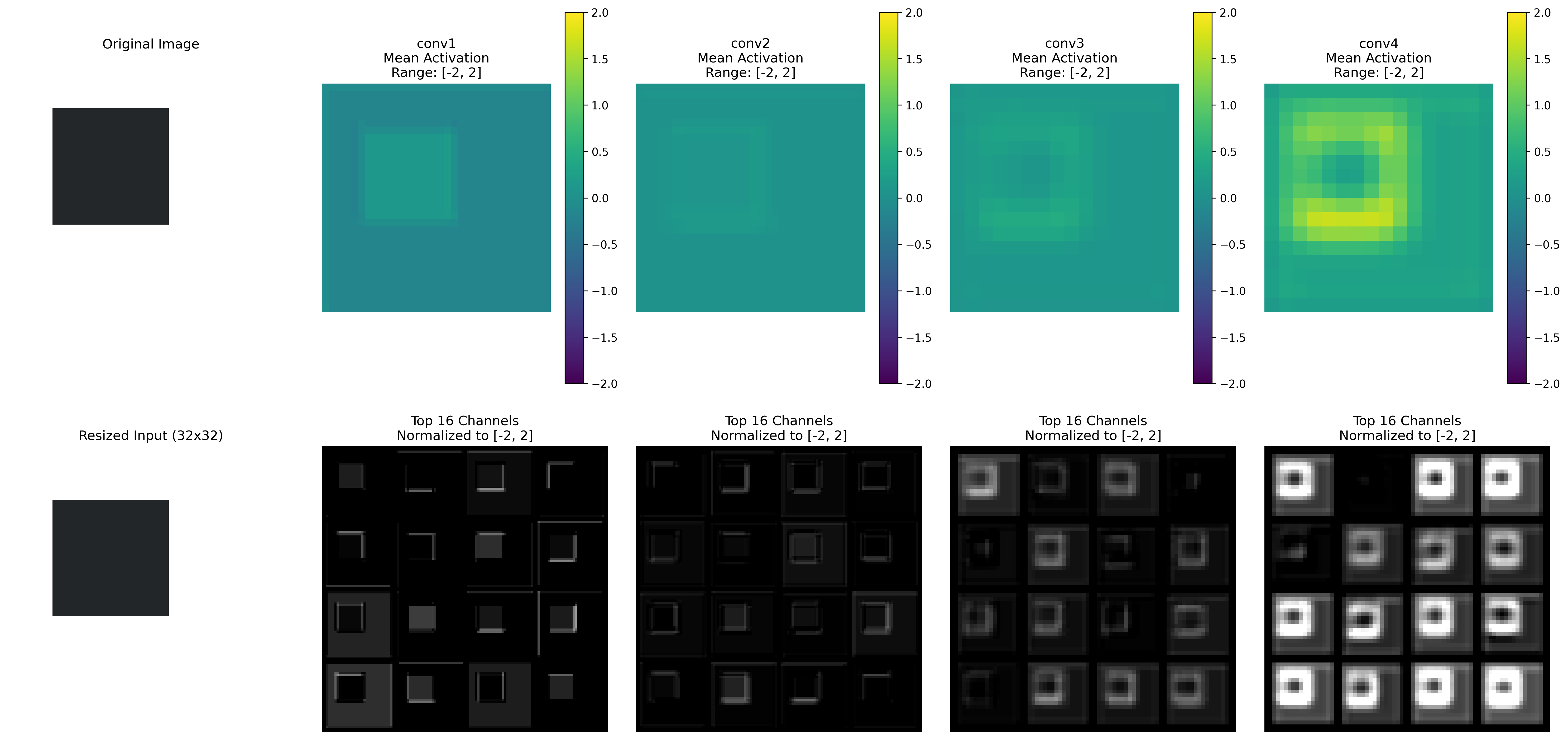
Key Takeaways#
This is an exciting result—by introducing a new dynamic into the dataset, we can clearly see how the model responds to the new signal.
These experiments demonstrate how even small changes in dataset design can significantly influence how deep learning models learn and interpret features. By carefully engineering the data, we can guide the development of the models’ feature extraction mechanisms, improving their accuracy and robustness.
It is crucial to inspect the model’s weights and activations to gain a full understanding of how the data influences learning and how well the model generalizes to data outside the training distribution. This approach not only enhances model performance but also opens new possibilities for targeted feature extraction and improved generalization in real-world applications.