
When I was a graduate student, I discovered Steven Wolfram’s book “A New Kind of Science.” The book was transformational for me and has shaped much of my work and thinking since then. One of the most important concepts in the book is the concept of computational irreducibility. These ideas sent me down a lifelong rabbit hole exploring the computational universe. Neural networks, specifically LLMs, have reached a level of sophistication that I would never have imagined seeing in my lifetime. However, despite their impressive capabilities, there are some fundamental limitations that are important to understand. These limitations are easy to miss if you haven’t been steeped in the subject of computation. I want to try to bring some of these ideas to a wider audience and maybe point out some important areas to explore as we move forward. When we think of superintelligence, we imagine an intelligent system that will unlock all the secrets of the universe. However, the secrets of the universe are just that—they are secrets, and learning patterns from the past alone will not unlock them.
Neural networks are powerful tools for pattern recognition and prediction, but they are often misunderstood. While these systems have made breakthroughs in fields like image recognition and natural language processing, they have fundamental limitations that restrict their ability to generate new knowledge or explore future possibilities. Neural networks are not Turing machines, they are not capable of true exploration, and they are not independent knowledge creators. Their function is to identify patterns within the data they have seen, not to imagine or reason beyond it. Understanding these limitations requires an examination of a deeper concept: computational irreducibility.
Computational irreducibility, a principle introduced by Stephen Wolfram, suggests that some systems are so complex that their future states cannot be predicted or simplified through shortcuts. The only way to know what will happen is to simulate the system step-by-step. In an irreducible system, no amount of historical data can fully reveal future dynamics. You must “run the computation” to discover new outcomes. This principle presents a fundamental challenge for neural networks, which are designed to approximate known patterns rather than simulate new processes. Neural networks, by their nature, are built to compress past data into a functional representation. They do not inherently engage in the type of forward, open-ended exploration that irreducible systems demand.
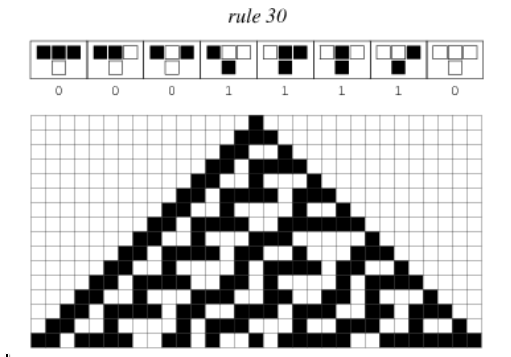
Neural networks do not compute in the way a Turing machine does. A Turing machine follows step-by-step rules to manipulate symbols and solve problems. Its logic is transparent, and each step can be traced and explained. Neural networks, by contrast, process information through layers of weighted connections and nonlinear functions. These operations resemble signal processing more than logical reasoning. The network does not “think” or apply abstract rules. It responds based on statistical relationships it has learned from past data. In irreducible systems, where outcomes cannot be predicted by static models, neural networks will always fall short because their function is to approximate relationships that have already occurred, not simulate processes that must be computed forward.
Neural networks are not capable of true exploration. These systems learn by extracting patterns from existing datasets. When they produce new outputs, they are not inventing or exploring new ideas; they are recombining patterns from their training data. Even advanced generative models that produce realistic images or coherent text rely entirely on previously observed patterns. The results may look new, but they are always drawn from historical information. Neural networks interpolate within known distributions—they do not extrapolate beyond them. This limits their usefulness in tasks that require imagination, hypothesis generation, or novel problem-solving. Exploration in irreducible systems requires running new computations and testing hypotheses in real-time, something traditional neural networks cannot do.
That said, neural networks can sometimes surprise us. Models trained on massive datasets sometimes produce outputs that feel novel or unexpected. This happens when the network finds patterns or connections that humans might have missed. In the latent space of these models, related concepts can cluster in surprising ways, occasionally linking ideas that seem disconnected to us. When a model generates an unusual insight, it may appear creative. But this isn’t genuine novelty—it’s the product of the model’s internal statistical landscape, not a leap beyond it. The network isn’t pushing into new conceptual territory; it’s revealing overlooked patterns within the existing dataset. What feels like creativity is, in fact, the model surfacing relationships that were statistically present but cognitively invisible to us. The model has not broken through irreducibility; it has simply exploited latent correlations from past data.
Neural networks do not create knowledge independently. The models are trained on labeled or unlabeled datasets, and their learning is limited to the patterns present in that data. They cannot form new concepts, question assumptions, or derive principles from first principles. For example, when a language model can generate text that resembles a scientific explanation. It is simply reproducing statistical patterns of language. Knowledge creation requires the ability to test, adapt, and generate new hypotheses, none of which neural networks can do on their own. In an irreducible domain, where genuine insight requires new computational experiments, these models lack the ability to break past the distribution they’ve already seen.
Some argue that LLM-based agents can reason, especially when given tools like calculators, databases, or even code execution environments. I believe that in the right configuration (for example, if an LLM was given agency over an algorithm or framework capable of modeling computationally irreducible systems) and if an LLM is given the right environment, this might turn out to be correct, although as of the time of writing this article, it hasn’t happened yet. In specific contexts, these systems can perform logical reasoning, solve novel problems, or even generate plausible hypotheses. But this type of reasoning happens entirely within the boundaries of the model’s statistical training. The LLM cannot independently test its ideas or gather new information unless it is connected to external systems capable of running experiments or retrieving real-world data. Without that feedback loop, the reasoning process is just pattern completion within the latent structure of past knowledge. In irreducible systems, where future outcomes depend on unpredictable factors, an LLM left to its own devices will only “reason” within the statistical echo of the past.
Neural networks are also not designed for open-ended exploration. The training process is optimized for specific tasks, minimizing a predefined error metric. This approach makes the network highly efficient at tasks it has been trained for but limits its ability to adapt to new environments or objectives. In nature, systems like evolution explore vast, uncharted spaces of possibilities, often producing unexpected results. Evolution is an example of an irreducible process: it cannot be predicted through any shortcut; you have to let it run. Neural networks, however, are constrained by their training objectives and cannot independently shift toward new, unanticipated goals. They do not “run the process” of discovery; they simulate the patterns that have already been run.
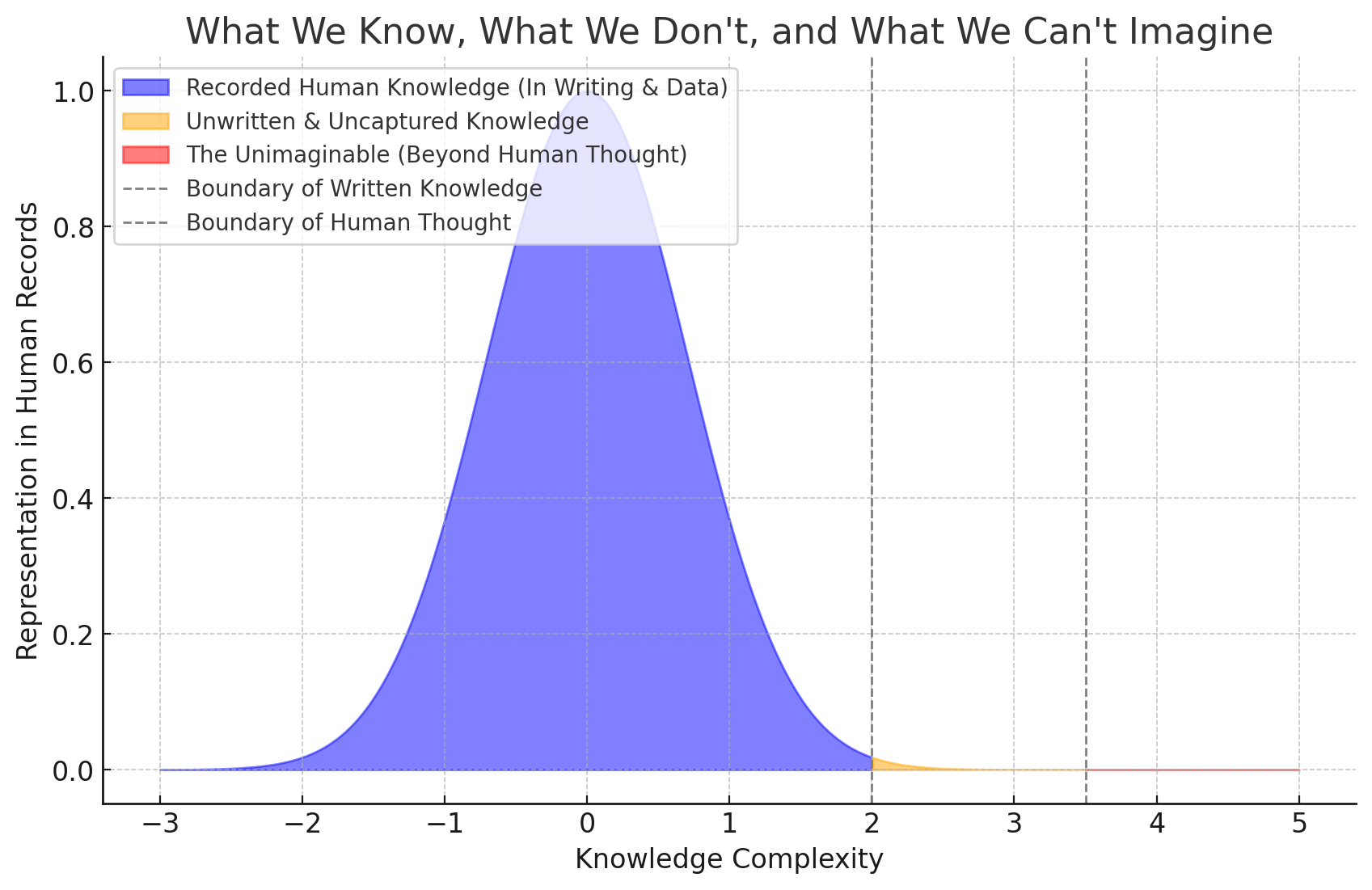
Recognizing these limitations is important for anyone interested in the future of artificial intelligence. Neural networks can replicate patterns from the past with remarkable accuracy, but they are not tools for discovering what has never been seen. If we want systems capable of true innovation or exploration, we need different approaches—possibly models that integrate evolutionary principles, curiosity-driven learning, or hybrid architectures that combine statistical learning with symbolic reasoning. Above all, we need architectures that can interact with the world, run computations forward, and learn from the results—rather than relying on static datasets of past observations. For now, neural networks remain firmly tied to the past, no matter how sophisticated their results may seem. In a world full of irreducible processes, that limitation matters.